https://www.coltsteele.com/tips/understanding-openai-s-temperature-parameter
Temperature is a number between 0 and 2, with a default value of 1 or 0.7 depending on the model you choose.
The temperature is used to control the randomness of the output.
When you set it higher, you'll get more random outputs. When you set it lower, towards 0, the values are more deterministic.
The message we send asks the model to complete the sentence "the key to happiness is" with two words.
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Complete the sentence with two words. The key to happiness is"}]
)
With the default temperature, running this will usually return "contentment and gratitude" or "inner peace".
If we increase the temperature parameter to the maximum of 2 by adding `temperature=2, it's going to give me a much more varied output: "personal fulfillment", "simplicity and gratitude", "contentment and balance", "satisfaction and appreciation", "different for everybody", "gratitude and teamwork", "mindfulness and empathy".
Moving the temperature all the way down to zero, it's going to return "contentment and gratitude" pretty much every single time. It's not guaranteed to be the same, but it is most likely that it will be the same output.
Haiku Example
In this example, we ask the model to write a haiku.
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature=0.9,
messages=[{"role": "user", "content": "Write a haiku"}]
)
With the temperature at 0.9, it's going to produce nice haikus that are typically nature-themed:
flowers in the field,
dancing in the summer breeze,
nature's symphony.
Solitary bee
over forgotten blossoms,
April cold leaves.
Moving the temperature all the way up to 2, we'll certainly get something different, but it won't always be coherent:
Easy tropical flips-
trade palms winds filter music_,
without flotates spring waves
First of all, this is not a haiku. It also starts introducing some very weird stuff like underscores and a made up word.
How Temperature Works
Basically, the temperature value we provide is used to scale down the probabilities of the next individual tokens that the model can select from.
With a higher temperature, we'll have a softer curve of probabilities. With a lower temperature, we have a much more peaked distribution. If the temperature is almost 0, we're going to have a very sharp peaked distribution.
https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683
Let’s start with temperature:
- Temperature is a parameter that controls the “creativity” or randomness of the text generated by GPT-3. A higher temperature (e.g., 0.7) results in more diverse and creative output, while a lower temperature (e.g., 0.2) makes the output more deterministic and focused.
- In practice, temperature affects the probability distribution over the possible tokens at each step of the generation process. A temperature of 0 would make the model completely deterministic, always choosing the most likely token.
Next, let’s discuss top_p sampling (also known as nucleus sampling):
- Top_p sampling is an alternative to temperature sampling. Instead of considering all possible tokens, GPT-3 considers only a subset of tokens (the nucleus) whose cumulative probability mass adds up to a certain threshold (top_p).
- For example, if top_p is set to 0.1, GPT-3 will consider only the tokens that make up the top 10% of the probability mass for the next token. This allows for dynamic vocabulary selection based on context.
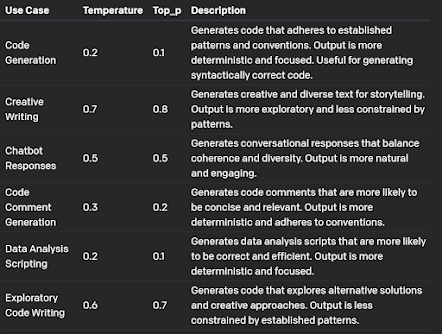
Both temperature and top_p sampling are powerful tools for controlling the behavior of GPT-3, and they can be used independently or together when making API calls. By adjusting these parameters, you can achieve different levels of creativity and control, making them suitable for a wide range of applications.
To give you an idea of how these parameters can be used in different scenarios, here’s a table with example values: